
We manually selected 150 images from the BOK-VQA benchmark dataset and an additional 150 images reflecting the cultural elements of each language from Wikimedia Commons. Subsequently, we utilized the GPT-4o model with few-shot samples to create the VLR-Bench benchmark dataset. VLR-Bench is a parallel corpus consisting of English, Chinese, and Korean, with a total of 300 samples. The VLR-Bench dataset is available at the following link: [HuggingFace Dataset].
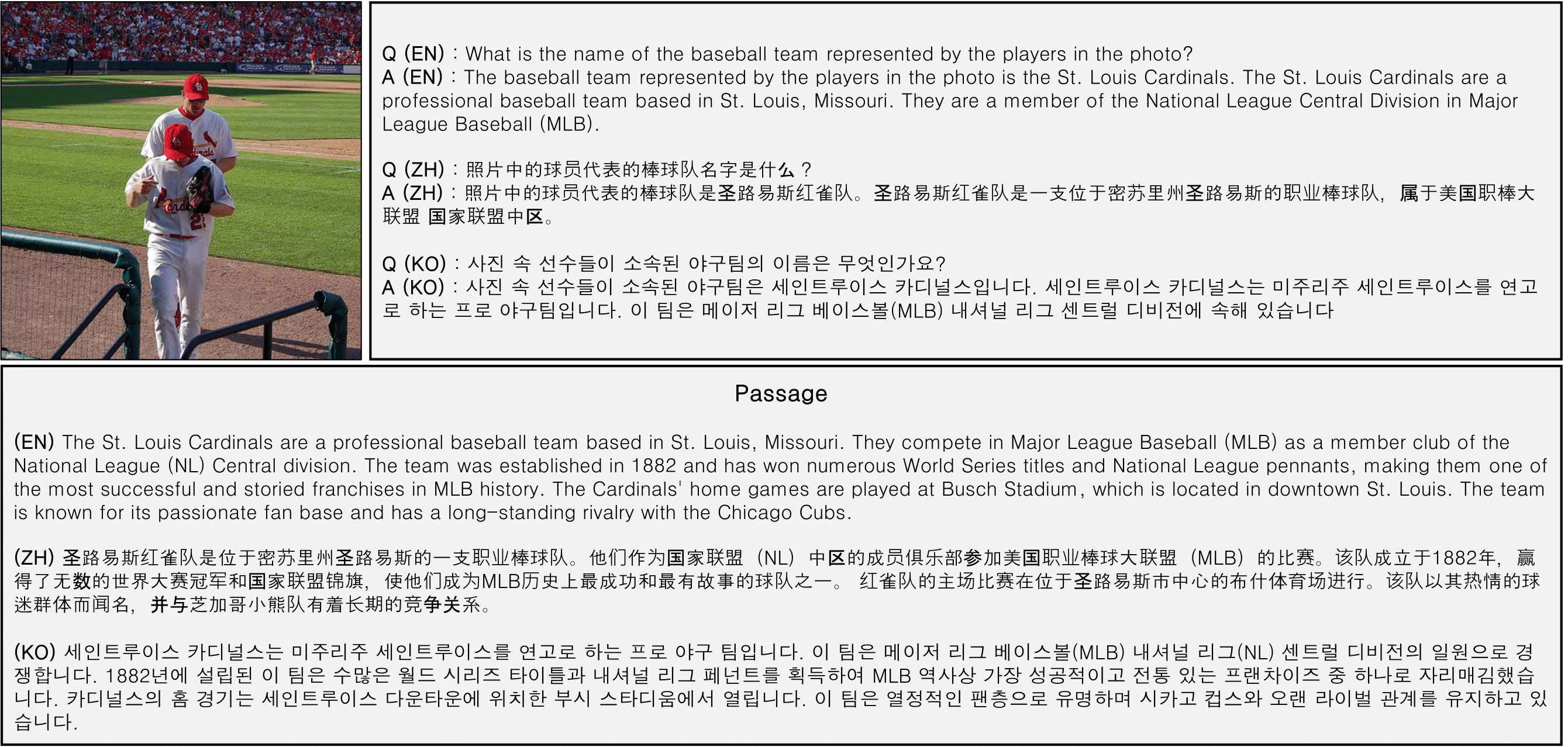
The following figures are examples from VLR-BENCH. Each example consists of a question, an answer, keywords, and passages. The “gold passage”, which contains the information necessary to answer the question, is highlighted in yellow.


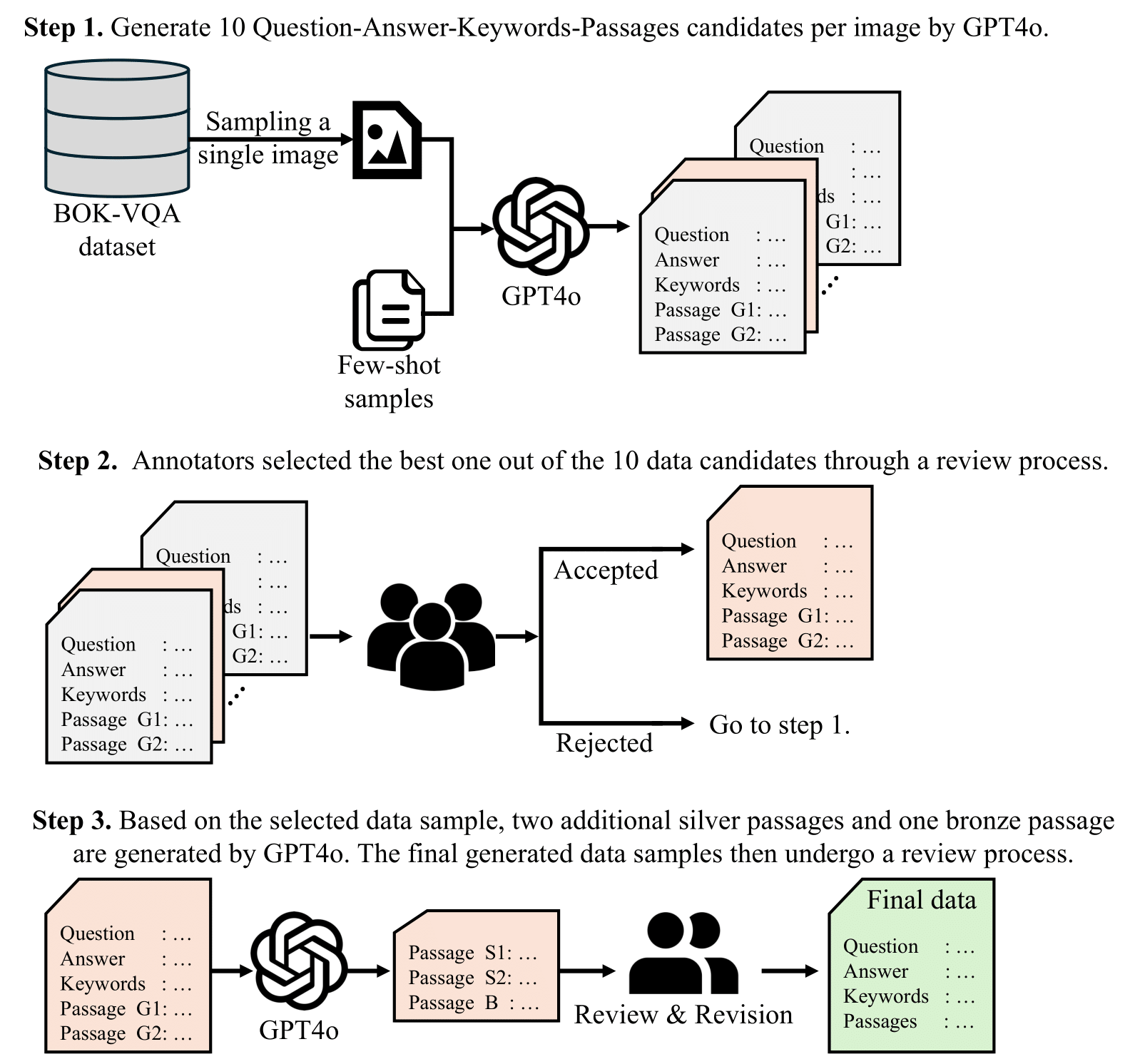
Before conducting evaluations with our VLR-Bench, we built the VLR-IF (Instruction Following) dataset to ensure the model can extract accurate information from documents. A total of 9,000 images were randomly selected from the COCO image dataset. Following a process similar to the construction of VLR-Bench, we provided few-shot examples to GPT-4o to generate "valid passages." Subsequently, we used valid passages from other image samples as "invalid passages" and combined them to create a parallel corpus of 32,000 entries spanning English, Chinese, and Korean. This dataset is available at the following link: [HuggingFace Dataset]. Ultimately, we constructed a total of 32,000 datasets by combining valid and invalid passages in the following manner: {V}, {I}, {V, I}, {V, I, I}.
@article{lim2024vlr,
title={VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation},
author={Lim, Hyeonseok and Shin, Dongjae and Song, Seohyun and Won, Inho and Kim, Minjun and Yuk, Junghun and Jang, Haneol and Lim, KyungTae},
journal={arXiv preprint arXiv:2412.10151},
year={2024}
}
@inproceedings{lim-etal-2025-vlr,
title = "{VLR}-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation",
author = "Lim, Hyeonseok and
Shin, Dongjae and
Song, Seohyun and
Won, Inho and
Kim, Minjun and
Yuk, Junghun and
Jang, Haneol and
Lim, KyungTae",
editor = "Rambow, Owen and
Wanner, Leo and
Apidianaki, Marianna and
Al-Khalifa, Hend and
Eugenio, Barbara Di and
Schockaert, Steven",
booktitle = "Proceedings of the 31st International Conference on Computational Linguistics",
month = jan,
year = "2025",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.coling-main.411/",
pages = "6150--6168",
abstract = "We propose the VLR-Bench, a visual question answering (VQA) benchmark for evaluating vision language models (VLMs) based on retrieval augmented generation (RAG). Unlike existing evaluation datasets for external knowledge-based VQA, the proposed VLR-Bench includes five input passages. This allows testing of the ability to determine which passage is useful for answering a given query, a capability lacking in previous research. In this context, we constructed a dataset of 32,000 automatically generated instruction-following examples, which we denote as VLR-IF. This dataset is specifically designed to enhance the RAG capabilities of VLMs by enabling them to learn how to generate appropriate answers based on input passages. We evaluated the validity of the proposed benchmark and training data and verified its performance using the state-of-the-art Llama3-based VLM, the Llava-Llama-3 model. The proposed VLR-Bench and VLR-IF datasets are publicly available online."
}
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant, funded by the Korea government (MSIT) (No.RS-2024-00456709, A Development of Self-Evolving Deepfake Detection Technology to Prevent the Socially Malicious Use of Generative AI) and Artificial intelligence industrial convergence cluster development project funded by the Ministry of Science and ICT (MSIT, Korea)& Gwangju Metropolitan City awarded to KyungTae Lim.
Usage and License Notices: The data and code is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.